Welcome to aparke’s blog!
前言
Hadoop Streaming是Hadoop提供的一个编程工具,它允许用户使用任何可执行文件或者脚本作为Mapper和Reducer,例如: 采用shell脚本语言中的一些命令作为mapper和reducer(cat作为mapper,wc作为reduce)
原理
Hadoop Streaming是Hadoop提供的一个编程工具,它允许用户使用任何可执行文件或者脚本作为Mapper和Reducer。
Hadoop Streaming是利用“标准输入”和“标准输出”与我们编写的Map和Reduce进行数据的交换。
那么,任何能够使用“标准输入”和“标准输出”的编程语言都应该可以用来编写MapReduce程序。
例如: 采用shell脚本语言中的一些命令作为mapper和reducer(cat作为mapper,wc作为reduce)
用法
Python实现
map.py#!/bin/env python
#-*- coding:UTF-8 -*-
import sys
for line in sys.stdin:
word_arr=line.strip().split(' ')
for word in word_arr:
print '%s\t%s' % (word,1)
reduce.py#!/usr/bin/env python
#-*- coding:utf-8 -*-
import sys
(last_key, sum) = (None, 0)
for line in sys.stdin:
(key, count) = line.strip().split('\t')
if last_key == key :
sum += int(count)
else :
if last_key : print '%s\t%s' % (last_key, sum)
(last_key, sum) = (key, 1)
if last_key : print '%s\t%s' % (last_key, sum)
集群提交
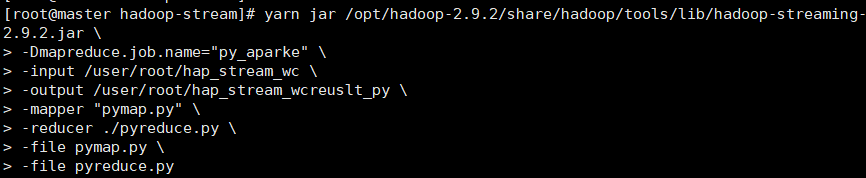
集群提交命令 |
命令解释 |
结果
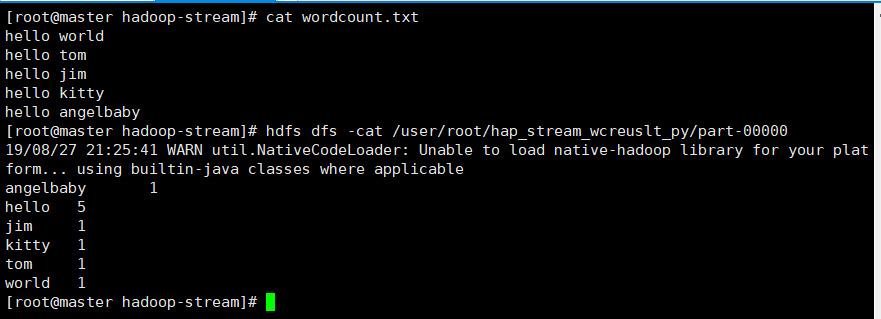
Shell实现
map.sh
|
reduce.sh
uniq -c | awk '{print$2"\t"$1}'
命令行提交
cat wordcount.txt | tr " " "\n" |sort| uniq -c | awk '{print$2"\t"$1}' |
shell 脚本提交
cat wordcount.txt | ./map.sh |sort| ./reduce.sh |
集群提交
yarn jar /opt/hadoop-2.9.2/share/hadoop/tools/lib/hadoop-streaming-2.9.2.jar \ |
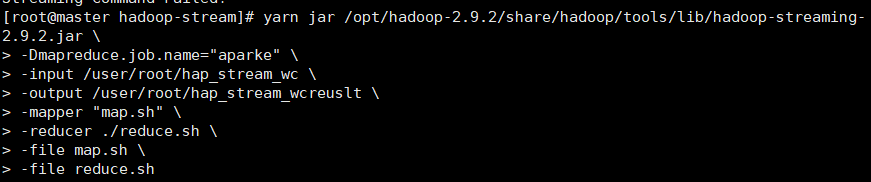
集群提交命令 |
|
结果