
Welcome to aparke’s blog!
摘要
出租车作为城市公共交通的重要组成部分,一定程度上满足了公众定制化出行需求。但是,定制出行需求的围观随机性和宏观性并存,有限的出租车资源和出行需求的时空分布给车辆调度造成较大的难度。出租车的区域性车辆调度问题已经成为智能交通领域的热点研究问题之一。
从出租车GPS轨迹数据中可挖掘出丰富的居民出行规律信息,但数据量的不断增加,对数据挖掘的准确性和效率提出了新的要求。传统的数据库已经不能实时处理海量数据下的出租车GPS轨迹记录。本文将以纽约市出租车GPS轨迹数据为研究对象,采用基于大数据hadoop、spark框架对数据进行分析,预测得到出租车的目的地和抵达时间。
1. 使用系统配置说明
1.1使用框架技术
1.1.1 Hadoop
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算。
1.1.2 HDFS
HDFS(Hadoop Distributed File System)是可扩展、容错、高性能的分布式文件系统,异步复制,一次写入多次读取,主要负责存储。
1.1.3 Spark
Spark 是一种与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使 Spark 在某些工作负载方面表现得更加优越,换句话说,Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。Spark 是在 Scala 语言中实现的,它将 Scala 用作其应用程序框架。与 Hadoop 不同,Spark 和 Scala 能够紧密集成,其中的 Scala 可以像操作本地集合对象一样轻松地操作分布式数据集。
1.1.4 Spark SQL
Spark sql是Spark处理数据的一个模块,跟基本的Spark RDD的API不同,Spark SQL中提供的接口将会提供给Spark更多关于结构化数据和计算的信息。其本质是,Spark SQL使用这些额外的信息去执行额外的优化,这儿有几种和Spark SQL进行交互的方法,包括SQL和Dataset API,当使用相同的执行引擎时,API或其它语言对于计算的表达都是相互独立的,这种统一意味着开发人员可以轻松地在不同的API之间进行切换
1.2配置说明
| 软件配置 | 说明 |
|---|---|
| Spark版本 | 2.4.0 |
| Hadoop版本 | 2.9.2 |
| Scala版本 | 2.11.12 |
| Jdk版本 | 1.8.0 |
| 内存master | 10G |
| 内存slave 8G | 8G |
| cpu master | 4个 |
| cpu slave | 2个 |
| 运行时长 | 10min-11min |
1.4集群提交
启动指令:bin/spark-submit --master spark://master:7077 \
--class cn.aparke.spark.geotime.RunGeoTime \
--driver-memory 8g \
--executor-memory 6g spark-geotime-2.0.0-jar-with-dependencies.jar \
hdfs://master:9000/catdata \
hdfs://master:9000/cat/hours hdfs://master:9000/cat/nopass \
hdfs://master:9000/cat/pass hdfs://master:9000/cat/result
说明
其中运行jar包需要使用4个参数,最少一个参数args(0)
args(0)为数据集的地址(HDFS)
args(1)为乘客乘车时间结果的路径
args(2)为未处理时间得到的每个地区的打车记录次数结果路径
args(3)为处理过滤了部分起点终点丢失后的结果路径
其中1,2,3参数可以为空 因为在spark-shell控制台中也会打印以上全部结果,比产生在文件中数据更为直观。
2. 收集出租车GPS轨迹数据
2.1准备数据集
下载地址: https://storage.googleapis.com/aas-data-sets/trip_data_1.csv.zip 数据是纽约市出租车数据,统计纽约市乘客下车点落在每个行政区的个数。解压缩之后,大约是2.5GB的数据。
2.2数据前10行

图2.1 数据集格式
报头后的文件的每一行代表CSV格式的单程出租车。对于每次乘坐,我们有出租车的一些属性(徽章编号的散列版本)以及司机(黑客许可证的散列版本,这就是驾驶出租车的许可证所称的),一些关于旅行开始和结束的时间信息,以及经度纬度乘客的位置和落在哪里的坐标。
2.3数据描述
| 参数 | 说明 |
|---|---|
| medallion: | UUID |
| hack_license: | UUID |
| vendor_id: | 类型 |
| rate_code: | 比率 |
| store_and_fwd_flag: | 是否是四驱 |
| pickup_datatime: | 客人上车时间 |
| dropoff_datatime: | 客人下车时间 |
| passenger_count: | 载客数量 |
| trip_time_in_secs: | 载客时间 |
| trip_distance: | 载客距离 |
| pickup_longitude: | 客人上车经度 |
| pickup_latitude: | 客人上车维度 |
| dropoff_longitude: | 客人下车经度 |
| dropoff_latitude: | 客人下车维度 |
3. 数据处理
3.1处理时间数据
3.1.1 Jode-Time 和NScalaTime处理时间数据
时间处理类库:joda-time,nscala-time_2.11.jar(2.11对应scala版本)
Jode-Time 介绍:
任何企业应用程序都需要处理时间问题。应用程序需要知道当前的时间点和下一个时间点,有时它们还必须计算这两个时间点之间的路径。使用 JDK 完成这项任务将非常痛苦和繁琐。既然无法摆脱时间,为何不设法简化时间处理?现在来看看 Joda Time,一个面向 Java平台的易于使用的开源时间/日期库。JodaTime轻松化解了处理日期和时间的痛苦和繁琐。
Joda-Time 令时间和日期值变得易于管理、操作和理解。事实上,易于使用是 Joda 的主要设计目标。其他目标包括可扩展性、完整的特性集以及对多种日历系统的支持。并且 Joda 与 JDK 是百分之百可互操作的,因此您无需替换所有 Java 代码,只需要替换执行日期/时间计算的那部分代码。
Joda-Time提供了一组Java类包用于处理包括ISO8601标准在内的date和time。可以利用它把JDK Date和Calendar类完全替换掉,而且仍然能够提供很好的集成。
3.1.2 NScalaTime封装库处理时间数据
Scala是可以直接调用java中的类java.time包,它基于JodaTime库设计的对所有地理空间应用场景都适用。
对于时间数据,当然有Java Date类和Calendar类。但是很难使用,并且需要大量的样板来进行简单的操作。JodaTime一直是处理时间数据的Java库
Scala提供JodaTime提供了额外的语法NScalaTime的包装库。
我们可以通过一个引入来使用它的所有函数:引入来使用它的所有函数:
import com.github.nscalatime.time.Imports.
JodaTime和NScalaTime都是基于DateTime类。DateTime对象是不可变的,如Java字符串(与常规Java API中的Calendar/Date对象不同),并提供了一些可以用于对时间数据执行计算的方法。
要将日期字符串表示为可计算的DateTime对象。使用Java的SimpleDateFormat ,对于解析不同格式的日期。
3.2处理地理数据
3.2.1 Esri Geometry API
租车记录的纬度和经度以及以GeoJSON格式存储的矢量数据表示纽约不同行政区的边界。使用Esri Geometry API解析GeoJSON数据并能够处理空间关系的库,比如检测给定的经纬度对是否包含在表示特定行政区边界的多边形内。
Java的Esri Geometry API,它具有很少的依赖性并且可以分析空间关系,但是只能解析GeJJSON标准的子集,使用它来做 GeoJSON数据的数据处理。
Esri Geometry API for Java可用于在第三方数据处理解决方案中实现空间数据处理。基于MapReduce的自定义Hadoop应用程序的开发人员可以使用此API对Hadoop系统中的数据进行空间处理。该API也被Hive UDF所使用,开发人员可以使用它为第三方应用程序构建几何函数,例如Cassandra,HBase,Storm和许多其他基于Java的“大数据”应用程序。
图3.1 Esri Geometry的子类们
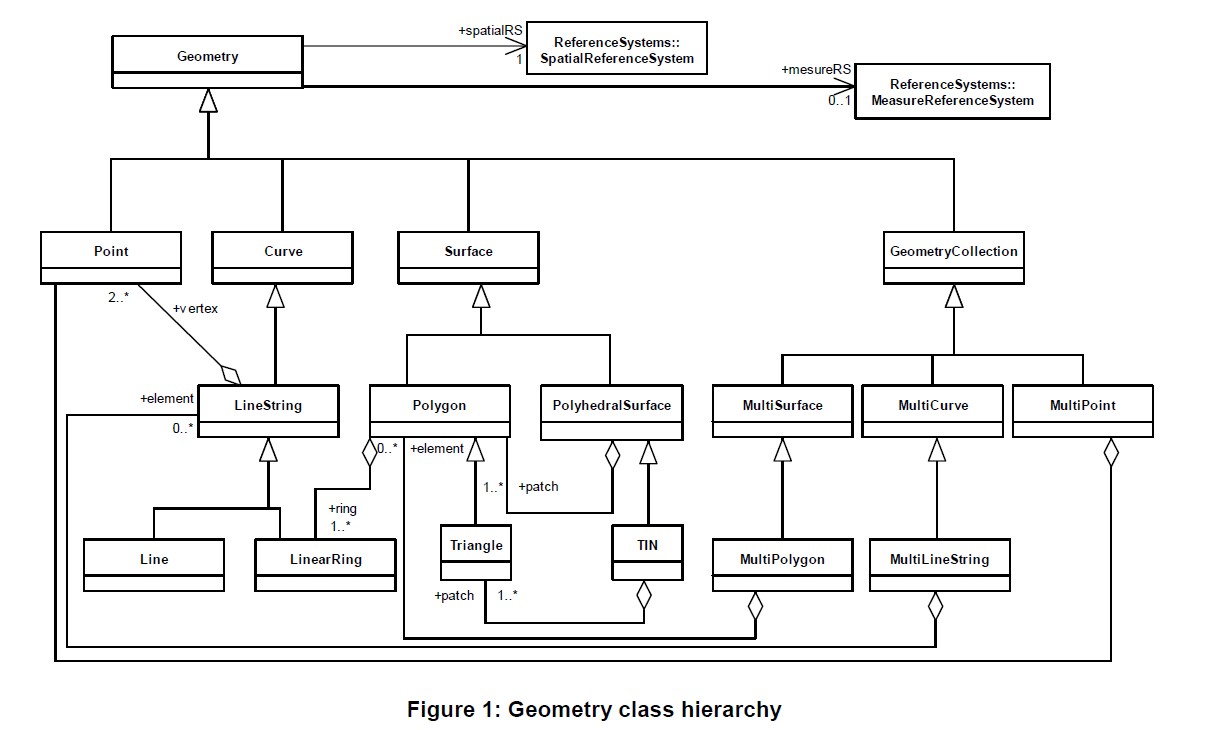
图3.2 Geometry的类层次结构
3.2.2 Esri Geometry API ESRI
Esri Geometry APIESRI库的核心数据类型是Geometry对象。Geometry描述的是一种形状和它所在的地理位置,ESRI提供了一组空间分析操作用于分析几何图像及其关系。伴随着一种地理位置。该库包含一组空间操作,允许分析几何结构及其关系。这些操作可以告诉我们几何的区域,告诉我们两个几何体是否重叠,或者计算由两个几何体的结合所形成的几何结构。
在案例中,我们将使用表示出租车出行点(经度和纬度)的几何图形,以及表示纽约市一个行政区边界的几何图形。猜测它们的包含关系:一个给定的位置点是否在曼哈顿区对应的多边形里边
Esri API提供了一个助手类GeometryEngine,它提供了所有空间关系操作的静态方法,其中就包括contains操作。Contains方法有三个参数:两个Geometry实例参数和一个spatitalReference实例参数。spatialReference实例参数表示用于地理空间计算的坐标系统。为了提高精度,我们需要分析相对于坐标平面的空间关系,该坐标平面将地球这个畸球体上的每个点映射到二维坐标系中。地理空间工程师有一组标准的众所周知的标识符(称为WKID),可以用来引用最常用的坐标系。为了我们的目的,我们将使用WKID 4326,它是GPS所使用的标准坐标系统。
检查出租车地理空间数据。对于每次行程,有一个经度纬度对,表示乘客被接到的地方,另一个表示他们被送下的地方。希望能够确定这些经度纬度对中的每一个属于哪个行政区,并确定没有在五个行政区中的任何一个开始或结束的行程。例如,如果出租车载乘客从曼哈顿到纽瓦克国际机场,那将是一次值得分析的有效旅程,即使它不会在五个行政区之一内结束。然而,如果看起来好像一辆出租车载着一名乘客去了南极,那么我们可以合理地确信记录是无效的,应该从我们的分析中排除。
3.2.3 GeoJSON简介
表示纽约市行政区域范围的数据是GeoJSON格式的,GeoJSON中核心的对象成为特征,特征是由一个geometry 实例和一组属性的键值对组成。其中geometry可以是点、线或者多边形。一组特征称为FeatureCollections。
下载纽约市行政区地图的GeoJSON数据。查看特性记录,有属性和几何对象——是表示行政区边界的多边形,以及包含行政区名称和其他相关信息的属性。
Feature : 特征
borough Code:行政区代码
borough:行政区
Polygon:多边形
coordinates:坐标
查看它一组数据分析展示的是Staten_Island(斯塔尼岛id为1)的行政区域的相关信息{
"type": "Feature",
"id": 1,
"properties": {
"boroughCode": 5,
"borough": "Staten Island",
"@id": "http://nyc.pediacities.com/Resource/Borough/Staten_Island"
},
"geometry": {
"type": "Polygon",
"coordinates": [
[
[
-74.05314036821109,
40.577702715545758
],
[
-74.05406044939875,
40.57711644523887
],
[
-74.05489778210804,
40.57778244091981
],
[
-74.05469316907487,
40.579691632229437
],
[
-74.05485134625391,
40.57970759307761
],
[
-74.05484560052175,
40.579945791427608
],
[
-74.05368629150419,
40.58054875961441
],
[
-74.05293190639817,
40.57990247466585
],
[
-74.05314036821109,
40.577702715545758
]
]
]
}
}
3.2.4 Spray处理地理数据
Esri Geometry API将帮助我们解析每个特性内部的几何JSON,需要使用Scala JSON库解析,使用Spray库。
Spray是一个开源的工具包,用于与Scala一起构建Web服务,它提供了一个符合任务的JSON库。Spray-json允许我们通过调用隐式toJson方法将任何Scala对象转换成相应的JSValue,并且还允许我们通过调用parseJson来将包含JSON的任何字符串转换成解析的中间形式,然后通过调用convertTo[T]将其转换为Scala类型T。Spray带有普通的Scala原语类型以及元组和集合类型的内置转换实现,并且它还具有一个格式化库,允许我们声明将RigGeometry类自定义类型转换为JSON的规则。
创建一个用于表示GeoJSON特征的case打车类。根据规范,一个特性是一个JSON对象,它需要具有一个与GeoJSON几何类型相对应的名为“geometry”的字段,和一个名为“properties“的字段,该字段是具有任意数量的任意类型的键值对的JSON对象。一个特性也可以有一个可选的“id”字段,它可以是任何JSON标识符。case类的Feature将为每个JSON字段定义相应的Scala字段,同时它还提供在属性map中查找值的辅助方法:import spray.json._
case class Feature(id: Option[JsValue],
properties: Map[String, JsValue],
geometry: RichGeometry) {
def apply(property: String): JsValue = properties(property)
def get(property: String): Option[JsValue] = properties.get(property)
}
使用RichGeometry类的实例来表示Feature中的geometry字段,通过Esri Geometry API的GeoJSON几何解析函数创建RichGeometry类实例。
定义一个FeatureCollection类,通过执行适当的apply和length方法来扩展IndexedSeq[Fask]特性,用来在FeatureCollection实例本身上调用标准的Scala Collections API方法,比如map、filter和sortBy.,而不必访问它所包装的底层Array[Feature]值:case class FeatureCollection(features: Array[Feature])
extends IndexedSeq[Feature] {
def apply(index: Int): Feature = features(index)
def length: Int = features.length
}
在定义了GeoJSON数据的case类之后还需要定义领域对象(RichGeometry, Feature, and FeatureCollection)与相应的JsValue实例转换的格式。
创建Scala 单例对象,扩展RootJsonFormat[T]特性,这个trian定义了抽象类 read(jsv: JsValue): T and write(t: T): JsValue。RichGeometry类,能解析和格式化大部分逻辑Esri geometry API,即GeometryEngine类上的geometryToGeoJson和geometryFromGeoJson方法。
对定义的case类,需要编写格式化逻辑,下面是Feature这个case类的格式化代码,其中包含了一些可选字段的id的特殊逻辑:implicit object FeatureCollectionJsonFormat extends RootJsonFormat[FeatureCollection] {
def write(fc: FeatureCollection): JsObject = {
JsObject(
"type" -> JsString("FeatureCollection"),
"features" -> JsArray(fc.features.map(_.toJson): _*)
)
}
def read(value: JsValue): FeatureCollection = {
FeatureCollection(value.asJsObject.fields("features").convertTo[Array[Feature]])
}
}
FeatureJsonFormat对象使用implicit关键字,在JSValue实例调用convertTo[Feature]方法时,Spray库可以查找它。
3.3纽约市出租车数据预处理
3.3.1上传数据到HDFSuzip trip_data_1.csv
hadop fs -put trip_data_1.c
Spark Shell 加载完成后,用出租车数据创建一个数据集,并检查下前几行的数据。val taxiRaw = spark.read.option("header", "true").csv(“hdfs://master:50070/catdata”)
taxiRaw.show()
3.3.3定义一个打车类
它包含了我们想在分析中使用的每个出租车出行的信息。我们将定义一个名为Trip的case类,它使用JodaTime API中的DateTime类来表示上车和下车时间,使用Esri Geometry API中的Point类来表示上车和下车位置的经度和纬度。
pickupTime,dropoffTime字段表示是长整型其值代表unix纪元以来的毫秒数,并将各个上下车的位置坐标的x,y坐标存储在单独的字段中,即就是将处理坐标值的方式转化为Esri API的point类的实例。case class Trip(
license: String,
pickupTime: Long, // 单位为 unix纪元以来的毫秒数
dropoffTime: Long,
pickupX: Double,//上车坐标 经纬度
pickupY: Double,
dropoffX: Double,//下车坐标
dropoffY: Double)
3.3.4数据集空值处理
数据中的某些字段很可能是丢失的,因此当我们从Row对象中读取它们的时候,需要确认下它们是否为空没否则程序会因为数据格式不对而终止程序,所以我们必须处理,RichRow类处理解析任何一种Row的对象。class RichRow(row: Row) {
def getAs[T](field: String): Option[T] =
if (row.isNullAt(row.fieldIndex(field)))
None
else Some(row.getAs[T](field))
}
在RichRow类中,getAs[T]方法总是返回一个option[T],而不是直接返回原始值。如果返回原始值,就处理解析一个Row对象时出现缺失字段的情况。根据数据集我们只需要处理Option[String]类型的值。因为数据集都是字符串。
3.3.5处理上下车时间
使用Java中的SimpleDateFormat类处理上下车时间,并且格式化字符串获得毫秒单位的时间:def parseTaxiTime(rr: RichRow, timeField: String): Long = {
val formatter = new SimpleDateFormat(
"yyyy-MM-dd HH:mm:ss", Locale.ENGLISH)
val optDt = rr.getAs[String](timeField)
optDt.map(dt => formatter.parse(dt).getTime).getOrElse(0L)
}
3.3.6解析上下车的经纬度
使用scala的隐式toDouble 的方法解析上下车位置的经纬度,将String隐式转换为Double,如果坐标缺失,则默认使用0.0def parseTaxiLoc(rr: RichRow, locField: String): Double = {
rr.getAs[String](locField).map(_.toDouble).getOrElse(0.0)
}
3.4大规模数据中的非法记录处理
在大数据处理中,如果数据集中有几条格式不能满足代码要求的,MapReduce作业和Spark在处理数据时会抛出异常,导致程序运行失败。
将try-catch块添加到解析代码中,从而可以将任何无效记录写入日志而不会导致整个作业失败。如果整个数据集中只有少数无效记录,那么可以忽略它们,继续进行分析。使用Spark,可以做得更好,调整解析代码,以能够交互地分析数据中的无效记录,对于RDD中的任何单个记录,解析代码都有两个可能的结果:要么成功解析记录,并返回有意义的输出,要么失败并抛出异常,在这种情况下,要将捕获无效记录的值被扔了。每当操作有两个互斥结果时,可以使用Scala的Either[L,R]类型来表示操作的返回类型。对我们来说,“左”结果就是成功解析的记录,“右”结果就是我们命中的异常和导致异常的输入记录的元组。
下面的safe函数接受类型为S T的名为f的参数,并返回一个新的S Either[T,(S,Exception)],该S Either[T,(S,Exception)]将返回调用f的结果,或者,如果抛出异常,则返回包含无效输入值和异常本身的元组。def safe[S, T](f: S => T): S => Either[T, (S, Exception)] = {
new Function[S, Either[T, (S, Exception)]] with Serializable {
def apply(s: S): Either[T, (S, Exception)] = {
try {
Left(f(s))
} catch {
case e: Exception => Right((s, e))
}
}
}
}
可以通过将解析函数(类型为String =>Trip)传递给safe函数,来得到一个更安全的包装函数safeparsed,然后在taxiRaw数据集底层的RDD上调用safeParseval safeParse = safe(parse)
val taxiParsed = taxiRaw.map(safeParse)
taxiParsed.cache()
通过获取值左边的元素,将taxiParsed RDD 转换为[Trip]实例:val taxiGood = taxiParsed.map(_.left.get).toDS
taxiGood.cache()
即使使用taxiGood RDD中的记录都可以正确解析,它们可能仍存在数据质量问题,这些问题需要进一步发现和处理。
考虑到行程数据的时间特性,任何乘车记录的下车时间都比上车时间晚,是一个合理的规则。同时,乘客的打车时间不能超过几小时,虽然可能也存在这样耗时比较长的乘车记录,比如高峰期时打车或遇到事故延误的情况时打车也是需要几个小时也是可以的。同样行程不会超过几个小时完成,尽管长途旅行、在高峰时间进行的旅行或因事故而延迟的旅行肯定会持续几个小时。我们不能确切地确定在一段“合理”的时间段内旅行的截止时间。
定义hours函数,该函数使用java的timeout方法来计算上下车的差值并从毫秒转换为数小时。val hours = (pickup: Long, dropoff: Long) => {
TimeUnit.HOURS.convert(dropoff - pickup, TimeUnit.MILLISECONDS)
}
然后我们可以使用它来计算taxigood RDD中从开始到结束的小时数的直方图:
taxiGood.groupBy(hoursUDF($"pickupTime", $"dropoffTime").as("h")).count().sort("h").
write.format("csv").save(args(1))

图3.3开始到结束的小时数的直方图
从上面的直方图,可以看出有一个-8小时,像这些数据,直接将它从记录中去掉。spark.udf.register("hours", hours)
val taxiClean = taxiGood.where("hours(pickupTime, dropoffTime) BETWEEN 0 AND 3")
3.5地理空间分析
现在我们从地理角度来检查出租车数据。对每次的乘车记录,各用一对经纬度来表示乘客的上车下车地点。需要确定这些经度/纬度对中的每一个属于哪个行政区,并确定没有在五个行政区中的任何一个开始或结束的行程。例如,如果出租车载乘客从曼哈顿到纽瓦克国际机场,就需要额外的处理,虽然它不在5个行政区中,但他也是合法的。当然如果打车的终点在南极,这就是非法记录必须剔除。
为了分析行政区,加载之前下载并存储在文件nyc-boroughs.geojson中的GeoJSON数据。scala.io包中的Source类使将文本文件或URL的内容作为单个String读入客户端中:val geojson = scala.io.Source.fromURL(this.getClass.getResource("/nyc-boroughs.geojson")).mkString
val features = geojson.parseJson.convertTo[FeatureCollection]
在使用出租车出行数据的特征之前,应该花点时间考虑如何组织这个地理空间数据,从而达到最大的效率。一种选择是研究为地理空间查找优化的数据结构。
find方法将遍历FeatureCollection,直到找到几何结构包含给定经度纬度点的特性。大多数出租车始于纽约,止于曼哈顿,所以如果代表曼哈顿的地理空间特征在序列中更早,那么大部分find调用将相对快速地返回。可以使用每个特性的boroughCode属性可以用作排序键,其中1代表曼哈顿,5代表斯塔滕岛。
对每个行政区的特征中,希望最大多边形相关的特征出现在较小的多边形之前,因为大多数行程将往返于每个行政区的“主要”区域。将每个特征的几何结构与boroughCode和area2D()的组合进行排序,然后根据行政区的代码和每个特征的几何模型area2D()大小来对特征排序,而且由于scala默认排序是由由小到大,所以根据area2D()取负值后进行排序的val areaSortedFeatures = features.sortBy { f =>
val borough = f("boroughCode").convertTo[Int]
(borough, -f.geometry.area2D())
}
此处我们需要注意的是基于area2D()值的负值进行排序,因为我们希望最大多边形优先,而Scala在缺省情况下按升序排序。
现在我们可以将frs序列中的排序特征广播到集群,并编写一个函数,该函数使用这些特征来找出特定行程以五个行政区(如果有的话)中的哪个结束:
将areaSortedFeatures 序列中排好序的特征广播到集群上,然后定义一个函数,利用这些特征来判断下车的点落在5个行政区的哪一个区val bFeatures = spark.sparkContext.broadcast(areaSortedFeatures)
val bLookup = (x: Double, y: Double) => {
val feature: Option[Feature] = bFeatures.value.find(f => {
f.geometry.contains(new Point(x, y))
}) feature.map(f => { f("borough").convertTo[String]
}).getOrElse("NA")
}
如果没有一个特性包含这次旅行的dropoff_loc,那么optf的值将是None,调用None值上的映射的结果仍然是None。我们可以把这个函数应用到taxitime RDD中的行程来创建横坐标是行政区的行程直方图。
在tailClean RDD中的打车记录应用boroughUDF,创建一个按行政区统计的直方图,args(2)保存通过未处理处理数据以上特征判断下车点落在五个行政区的哪一个中。taxiClean.groupBy(boroughUDF($"dropoffX", $"dropoffY")).count().write.format("csv").save(args(2))

图3.4未处理数据前
以上打印出的记录,是未处理数据以上特征得到的结果,会发现他们大部分的起点和终点都落在(0.0 0.0 )上,表明这些记录的期待你和终点数据缺失,将这种例外情况过滤掉。
重新在taxi RDD上运行分析,得到下面的结果,args(3)保存通过处理处理数据以上特征判断下车点落在五个行政区的哪一个中。val taxiDone = taxiClean.where("dropoffX != 0 and dropoffY != 0 and pickupX != 0 and pickupY != 0")
taxiDone.groupBy(boroughUDF($"dropoffX", $"dropoffY")).count().write.format("csv").save(args(3))
taxiGood.unpersist()
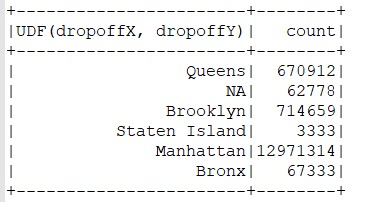
图3.5处理数据后
过滤起点或终点为零的记录后,5个行政区的输出记录只是减少了一些,但NA对应的记录大部分被去掉了,剩下的那些中带你落在郊区的记录条数,我们的零点过滤器从输出区移除了少量的观察,但是它移除了很大一部分None条目,留下更多更合理的观测值,这些观测值已经从城市外部下降。
4. Spark sql 会话分析
4.1会话分析简述
会话可以是一个非常强大的技术,用于发现数据中的洞察力,以及用于构建可用于帮助人们做出更好决策的新数据产品。例如,Google的拼写纠正引擎构建在用户活动会话之上,Google每天从其web属性上发生的每个事件(搜索、点击、地图访问等)的日志记录中构建用户活动会话。为了识别可能的拼写校正候选者,Google处理这些会话,寻找用户输入了哪些查询,点击哪些内容,在几秒钟后输入了稍微不同的查询,然后单击结果而没有返回Google的情况。然后,统计该模式对于任何一对查询的发生频率。如果它出现得足够频繁(例如,如果每次我们看到查询“untied stats”,几秒钟之后就会出现查询united states”),那么我们假设第二个查询是第一个查询的拼写纠正。该分析利用事件日志中表示的人类行为模式,比从字典中创建的任何引擎更强大的数据中构建拼写校正引擎。引擎可以用任何语言执行拼写纠正,并且可以纠正可能未包括在任何字典中的单词(例如,新启动的名称),甚至可以纠正查询,比如“解开统计”,其中没有单词拼错!Google使用类似的技术来显示推荐的和相关的搜索,以及决定哪些查询应该返回OneBox结果,该结果给出搜索页面本身上的查询的答案,而不需要用户单击另一个页面。有针对天气,体育比赛,地址,和许多其他种类的查询的OneBox.
4.2采用spark会话分析
前面描述提到的一个目标时要研究出租车乘客下车区域与出租车等待下一单生意的等待时间的关系。此时taxiDone RDD数据集包含每个出租车司机的所有的载客数据,这些记录分布在数据的不同分区上。为了计算一次行程的结束和下一次行程的开始之间的时间长度,为了计算一次载客结束到下次载客开始的时间间隔,需要把一个班次中的所有载客数据按一个司机一条记录进行汇总,然后把该班次中的载客记录按时间排序。排 序可以比较一次载客记录的下车时间和一次载客的上车时间。这种对单个实体载不同时间的一系列事件的分析称为会话分析,通常通过web日志执行,以便分析网站的用户的行为。
到目前为止,关于发生在每个实体上的一组事件的信息分布在RDD的分区中,因此,为了进行分析,我们需要将这些相关事件彼此相邻并按时间顺序排列。
4.3构建会话:基于Spark的二级排序
在Spark中创建会话的方法是对要为其创建会话的标识符执行groupBy,然后根据时间戳标识符对对打乱次序后的事件进行排序。由于这种方法要求任何特定实体的所有事件同时在内存中,因此它会随着每个实体的事件数量越来越大而扩展。需要一种构建会话的方法,该方法不需要在排序时将一个实体的所有事件同时放入内存。
在MapReduce中,我们可以通过二级排序构建会话,做法是创建一个由标识符和时间戳值组成的组合键,根据该组合键上的所有记录进行排序,然后使用自定义分区器和分组函数来确保所有记录具有相同的ID赋值符出现在同一个输出分区中。使用spark的repartition和sortWithinparttions转换,对数据集进行会话处理val sessions = taxiDone.
repartition($"license").
sortWithinPartitions($"license", $"pickupTime").
cache()
使用repatition方法,确保Trip记录中所有license列值相等的记录被分在配在同一个分区中。然后,在每个分区中,按照license的值对记录进行排序,完成后每个分区中的行程都是排好序的。
4.4计算接单时间
分析会话数据,看看司机在特定地区下车后要花多长时间才能接到下一单。创建一个boroughDuration方法,它接受两个Trip实例作为参数,计算第一个trip的区域以及第一个trip的下车时间和第二个Trip的上车时间Duration:def boroughDuration(t1: Trip, t2: Trip): (String, Long) = {
val b = bLookup(t1.dropoffX, t1.dropoffY)
val d = (t2.pickupTime - t1.dropoffTime) / 1000
(b, d)
}
将上面这个函数应用在所有会话数据集的连续的两个载客记录上val boroughDurations: DataFrame =
sessions.mapPartitions(trips => {
val iter: Iterator[Seq[Trip]] = trips.sliding(2)
val viter = iter.filter(_.size == 2).filter(p => p(0).license == p(1).license)
viter.map(p => boroughDuration(p(0), p(1)))
}).toDF("borough", "seconds")
在Sliding()方法的结果上,调用filter保证忽略掉只有一次载客记录的会话,或者在license字段上具有不同值的任意成对的载客记录。在会话之前进行mapPartitions操作的结果是一个由键-值对borough/duration组成的DataFrame。
4.5得到结果
boroughDurations. |
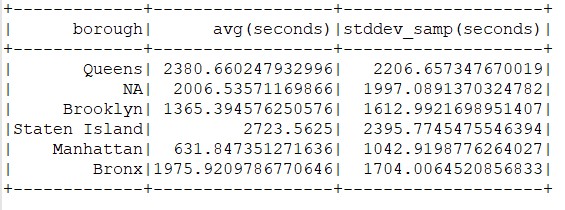
图3.7结果
数据结果显示Manhattan(曼哈顿)地区的等待时间最短,为10分钟左右,这个结果是意料之中的结果。布鲁克林地区的等丹时间超过曼哈顿地区的两倍,乘客下车点在史丹顿岛地区的次数相对较少,司机的平均接单时间约为45分钟。
5. 总结
在出租车数据上使用相同的大数据技术,根据当前交通模式和包含在此数据中的下一个最佳位置的历史记录,构建一个应用程序,该应用程序可以推荐出租车下车后的最佳位置。您还可以从试图搭乘出租车的人的角度来看待这些信息:给定当前时间、地点和天气数据、是否为早晚高峰,什么路段经常堵车,或者一些容易发生事故的地方。通过海量的数据集,加上这些参数,构建出新的模型,在通过SparkStreaming来实时预测,这样可以方便顾客更快、更廉价的方式打到车,同时出租车司机也可以通过更精准的大数据预测,从而推荐打车离自己位置更近,更加节省成本。类似这样的构思都可以加入到百度地图这些中。
由于时间仓足,以上提出的基于当时环境预测出租车目的地和抵达时间都没在我的案例中实现。还有用到了好多Scala语法,以及spark sql等技术,还是初学者,了解比较浅。通过在这次比赛后将上述描述的情景加入到代码中,可以更精准的进行智能预测操作。
感谢学校这次机会,参加这次比赛,提高自己项目能力和写作能力。
参考文献
[1] http://spark.apache.org/docs/latest/
[2] http://spark.apache.org/docs/2.1.1/sql-programming-guide.html
[3] https://github.com/Esri/geometry-api-java/wiki
[4] https://www.cnblogs.com/17th-trackwalker/p/10338957.html
[5] https://www.jianshu.com/p/3693c3cff55e
[6] https://blog.csdn.net/shujuelin/article/details/87819291
[7] https://zj793039327.github.io/code-2017-08-04-scala-uncommon-problem.html
[8] https://blog.csdn.net/Liunene/article/details/81037114
[9] [美]里扎(SandyRyza)、[美]莱瑟森(UriLaserson)、[英]欧文(SeanOwen)、[美]威尔斯(JoshWills)《Spark高级数据分析》
[10] http://www.doc88.com/p-8496339760556.html
[11] 许云峰, 李媚, 白宇, 张妍, 潘德芬. 大数据和人工智能实验指导书. 河北科技大学大数据实验室.

