
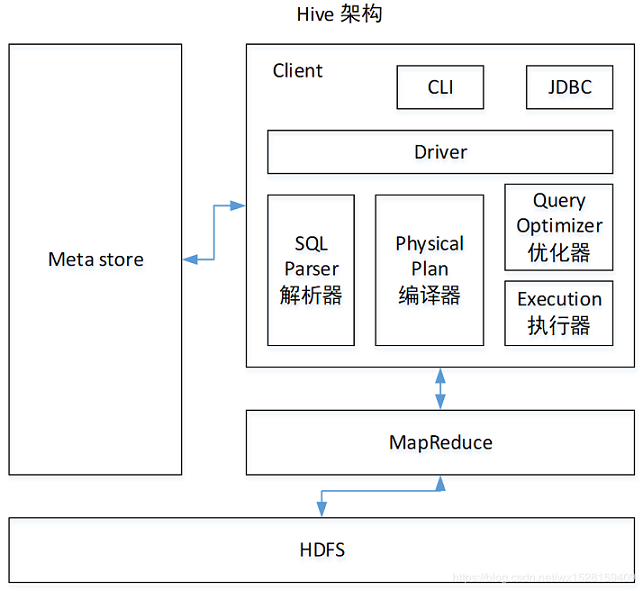
hive建库建表与数据导入
建库建表
hive中有一个默认的库:
库名: default
库目录:hdfs://192.168.179.200:9000/user/hive/warehouse
建内部表
新建库:create database db1;
库建好后,在hdfs中会生成一个库目录:
hdfs://192.168.179.200:9000/user/hive/warehouse/db1.db
例子use db1;
create table t_movie(id string,name string ,daoyan string)
row format delimited
fields terminated by ',';
本地数据 t_movie.dat1,zhanlang2,wujing
2,liulangdiqiu,guofan
3,fengkuangwaixinren,ninghao
4,feichirensheng,hanhan
上传至创建的表的hdfs目录下hadoop fs -put t_movie.dat /user/hive/warehouse/db1.db/t_movie
使用hive查看select * from t_movie;
OK
t_movie.id t_movie.name t_movie.daoyan
1 zhanlang2 wujing
2 liulangdiqiu guofan
3 fengkuangwaixinren ninghao
4 feichirensheng hanhan
Time taken: 0.339 seconds, Fetched: 4 row(s)
建外部表:
关键字external locationcreate external table t_test1(id int,name string,age int,create_time bigint)
row format delimited
fields terminated by '\001'
location '/external/t_test';
例子create external table t_pv_log(ip string,url string,access_time string)
row format delimited
fields terminated by ','
location '/external/pvlog/20190308';
将本地的数据上传到locationd的位置下
hdfs dfs -put pv.log /external/pvlog/20190308hive (db1)> show tables;
tab_name
t_movie
t_pv_log
t_test1
hive (db1)> select * from t_pv_log; |
注意
删除表后内部表在hdfs也被删了
而外部表还存在hdfs上drop table t_pv_log;
查看hdfs还在
再次创建表自动加载hdfs中的数据。
分区表
例子create table t_log(ip string ,url string,access_time string)
partitioned by(day string) #设置指定分区标记为(day)
row format delimited
fields terminated by ',';
hive (db1)> load data local inpath '/root/hive1/pv.log.5' into table t_log partition(day='20190305'); |
加载本地数据(local 如果是hdfs就不需要local) 并且给定值为day=20190305hive (db1)> load data local inpath '/root/hive1/pv.log.4' into table t_log partition(day='20190304');
hive (db1)> select * from t_log; |
(查询出来后,会出现一个伪字段 为分区字段 设置分区字段时不能和本身字段相同 )t_log.ip t_log.url t_log.access_time t_log.day
192.168.33.3 http://www.aparke.cn/stu 2019-03-04 15:30:20 20190304
192.168.33.3 http://www.aparke.cn/teach 2019-03-04 15:35:20 20190304
192.168.33.4 http://www.aparke.cn/stu 2019-03-04 15:30:20 20190304
192.168.33.4 http://www.aparke.cn/job 2019-03-04 16:30:20 20190304
192.168.33.5 http://www.aparke.cn/job 2019-03-04 15:40:20 20190304
192.168.33.3 http://www.aparke.cn/stu 2019-03-05 15:30:20 20190305
192.168.44.3 http://www.aparke.cn/teach 2019-03-05 15:35:20 20190305
192.168.33.44 http://www.aparke.cn/stu 2019-03-05 15:30:20 20190305
192.168.33.46 http://www.aparke.cn/job 2019-03-05 16:30:20 20190305
192.168.33.55 http://www.aparke.cn/job 2019-03-05 15:40:20 20190305
查询在2019-03-05中访问stu页面的次数select count(1) from t_log where url='http://www.aparke.cn/stu' and day='20190305';
查询访问stu页面的次数select count(1) from t_log where url='http://www.aparke.cn/stu';
建一个与之前存在表结构相似的表结构create table t_log_2 like t_log;
查看表结构desc t_log_2;
col_name data_type comment |
将数据文件导入hive的表
- 方式1:导入数据的一种方式:
手动用hdfs命令,将文件放入表目录; 方式2:在hive的交互式shell中用hive命令来导入本地数据到表目录
hive>load data local inpath '/root/order.data.2' into table t_order;
方式3:用hive命令导入hdfs中的数据文件到表目录
hive>load data inpath '/access.log.2017-08-06.log' into table t_access partition(dt='20170806');
注意:
导本地文件和导HDFS文件的区别:
本地文件导入表:复制
hdfs文件导入表:移动

